
Multi-Cloud Detection at Scale: A Normalization Framework
Building cloud-agnostic security data lakes with Bronze-Silver architecture and schema-first engineering

Podcast version generated using NotebookLM
In my previous blog post on building a cloud-native threat detection engineering handbook, I touched on the critical importance of upstream investment in telemetry quality versus downstream firefighting of false positives. The response was overwhelming - security practitioners across the industry resonated with this paradigm shift, but wanted deeper technical guidance on implementation.
This post focuses on the foundational layer that makes everything else possible: schema normalization and the Bronze-Silver architecture. While standards like Elastic Common Schema (ECS) and Open Cybersecurity Schema Framework (OCSF) exist, most teams struggle with practical implementation: How do you design schemas that won’t break when adding new cloud providers? How do you prevent cascading failures when fields change? How do you maintain detection rules that mirror your normalized schema? You’ll see real YAML configurations, concrete schema design patterns, and the architectural decisions that separate teams who successfully normalize from those who fail.
Every hour your security analysts work, they waste 15 minutes chasing false positives. That’s not a typo - it’s the harsh reality of modern Security Operations Centers (SOCs). With organizations handling anywhere from 500 to 3,000+ alerts daily, and false positive rates hovering between 40-60%. But here’s what most security leaders miss:
The problem isn’t your detection rules. It’s your data.
The Multi-Cloud Reality: Why Schema Fragmentation is Your Achilles’ Heel
Let’s start with why we’re in this mess. According to Gartner’s 2024 cloud strategy research, 92% of large enterprises operate multi-cloud environments today, and for good reason.
Best-of-breed service selection drives platform diversity. Organizations choose AWS for compute and storage scalability, GCP’s BigQuery for advanced analytics, and Azure for identity management and seamless Microsoft 365 integration. Cost optimization delivers compelling returns, with enterprises reporting significant savings through strategic provider selection and commitment discounts. Risk mitigation through geographic and provider diversity drives adoption, with organizations using multi-cloud for application isolation, disaster recovery, and failover capabilities.
But there’s a hidden tax that most organizations underestimate: schema fragmentation.
The same “User Login” event has four completely different schemas across AWS, GCP, Azure, and Oracle. Field names differ. Data types vary. Nested structures conflict. The consequences are severe. According to Orca Security’s 2022 Cloud Security Alert Fatigue Report, 91% of organizations report that point tools create blind spots affecting threat prevention, and 54% cite complexity and fragmentation as their top data security problem.
Without normalization, you must maintain three separate detection queries, each with different field mappings, testing requirements, and failure modes. When you add Oracle Cloud or Alibaba next year, you rewrite everything again. This doesn’t scale.
Organizations face hundreds of potential attack paths across their multi-cloud environment. Security teams spend the majority of their time on schema wrangling and data transformation instead of threat hunting. This is technical debt masquerading as security engineering.
The Bronze-Silver-Gold Architecture: Building the Foundation
The solution isn’t more detection tools. It’s better data architecture.
The medallion architecture for security data lakes is a layered approach borrowed from modern data engineering that progressively refines raw telemetry into actionable intelligence. The architecture consists of three layers: Bronze (raw, immutable logs), Silver (normalized, validated data), and Gold (enriched with business and threat context). Each layer serves a specific purpose and builds upon the previous one.
This article focuses on the foundational Bronze and Silver layers - the normalization infrastructure that makes everything else possible. Without robust normalization, enrichment becomes a per-provider problem that doesn’t scale. The Gold layer enrichment and AI-powered operations will be covered in detail in the next article.
Bronze Layer: The Immutable Truth
The Bronze layer stores raw logs exactly as received from CloudTrail, GCP Audit Logs, and Azure Activity Logs. No transformations. No data loss. Just append-only, immutable storage. This serves as your source of truth for forensics and compliance, enabling replay if normalization logic changes down the line. The format is typically JSON or Parquet with metadata including source, timestamp, and batch ID. The key principle is simple: preserve original fidelity. When you’re defending against a breach in court or conducting forensic analysis, you need the raw logs exactly as they were generated.
Silver Layer: The Normalized Schema
This is where the architectural magic happens. The Silver layer transforms heterogeneous cloud logs into a unified schema. Using standards like Elastic Common Schema (ECS) v9.2 or Open Cybersecurity Schema Framework (OCSF), you create a common language across all cloud providers.
Future-Proofing: How to Normalize Tomorrow’s Clouds Today
Here’s where most teams fail: they hard-code AWS/GCP/Azure mappings and then panic when Oracle Cloud enters the picture. The extensible approach requires architectural patterns that separate industry leaders from followers.
Schema-First Detection Engineering: Why Data Modeling is Pivotal
While ECS and OCSF provide excellent starting points, many organizations need customized schemas. Enterprise environments often require domain-specific fields, legacy system integration, or compliance-driven data models that don’t map cleanly to public standards. The key is building schemas that are both flexible and robust.
Before diving into schema design patterns, understand this critical truth: detection engineers must spend considerable time on data modeling before writing a single detection rule. This is not optional overhead - it’s the foundation that determines whether your detection engineering scales or collapses.
Here’s the workflow inversion that separates mature detection engineering from ad-hoc alerting
Design your schema before writing the detection, not after.
The broken pattern: write a detection idea, then scramble to extract the necessary fields from raw logs, then wonder why the query is 50 lines of complex joins and transformations. The production pattern: before writing a single line of detection logic, explicitly design what the input schema for that detection should look like.
Example: Service Account Activity Baseline Deviation
You want to detect when a service account performs an action it’s never done before. Before writing any detection code, ask: what does the ideal input schema look like?
# Canonical schema for behavioral baseline detection
service_account_event:
user:
identity: "ml-training-sa@company.com"
type: "service_account"
action:
type: "create_iam_user" # Current action
source:
ip: "203.0.113.42"
user_agent: "Mozilla/5.0 (browser)"
# BASELINE PARENT FIELD - this is the key
baseline:
action_types: ["deploy_function", "update_function", "read_logs"]
source_ips: ["10.0.1.45", "10.0.2.78"]
user_agents: ["aws-cli/2.1.0", "terraform/1.5.0"]
typical_resources: ["lambda-prod-*", "s3-deployment-*"]
first_seen: "2024-01-15"
last_seen: "2024-12-10"Once you’ve designed this canonical schema, your detection becomes trivial:
-- Simple, readable detection enabled by schema design
SELECT
user.identity,
action.type,
source.ip,
source.user_agent
FROM service_account_events
WHERE action.type NOT IN baseline.action_types
OR source.ip NOT IN baseline.source_ips
OR source.user_agent NOT IN baseline.user_agentsThe workflow:
Design the detection schema - What fields make this detection obvious to express?
Build transformation functions - Create normalization logic that produces this exact schema
Write the detection - Now it’s 5 lines instead of 50
This inverts the typical approach where teams write complex detections because their normalized schema wasn’t designed with detection use cases in mind
If your detection logic is complex, your schema design is wrong. The complexity should live in the transformation layer (which runs once during normalization), not in the detection layer (which runs constantly).
Schema design checklist for detections:
1. Action Taxonomy
Are provider-specific API calls mapped to semantic action types? (
CreateBucket→storage-create)Does the action taxonomy support detection logic without cloud-specific knowledge?
Are related actions grouped consistently? (
create|read|update|delete)
2. Metadata Enrichment
Is cloud provider/account/region extracted and normalized?
Are resource identifiers standardized across providers? (AWS ARN vs GCP URI vs Azure Resource ID)
Is user/principal type classified consistently? (
human|service_account|system)
3. Multi-Environment Support
Does the schema support filtering by environment? (
production|staging|development)Can you distinguish service categories? (
compute|storage|database|network)Are organizational boundaries preserved? (accounts, projects, subscriptions)
4. Temporal Context
Are timestamps normalized to a standard format? (ISO 8601, Unix epoch)
Is date partitioning abstracted for efficient queries?
Are lookback windows supported without complex date arithmetic?
5. Detection Simplicity Test
Can the majority of tripwire detections be expressed as simple WHERE clauses?
Do behavioral or correlation detections require complex joins, or is context pre-enriched?
Would a junior analyst understand the schema fields without deep documentation?
6. Schema Evolution Path
Can you add new cloud providers without breaking existing queries?
Are optional fields clearly distinguished from required fields?
Does the schema support gradual migration from legacy sources?
If the detection requires complex logic, iterate on the schema until it becomes simple. This is the difference between detection engineering as tribal knowledge (only the author understands it) versus detection engineering as a repeatable practice (any team member can maintain it).
Service Category Abstraction:
Don’t just normalize cloud providers - normalize service types within clouds. This enables detection logic that spans categories without enumerating every action.
# Schema includes service category
event:
service_category: "compute" # compute|storage|network|control_plane
cloud_provider: "aws"
action_type: "instance-create"This enables powerful queries:
-- Alert on any control plane activity by terminated users
SELECT * FROM cloud_audit_logs_silver
WHERE service_category = 'control_plane'
AND user.owner_status = 'terminated'
-- Alert on any production storage modifications
WHERE service_category = 'storage'
AND action_type = 'permission-modify'
AND resource.environment = 'production'Without service categories, you’d need to enumerate every control plane action across every cloud (EKS.CreateCluster, GKE.CreateCluster, AKS.CreateManagedCluster, etc.). The category abstraction makes detections resilient to new action types.
Multi-Tenant Table Filtering:
Large-scale systems often consolidate multiple services into single tables. Use metadata-based filtering to avoid schema fragmentation:
python
# Single table contains: Compute + Storage + Control Plane logs
# Filter by service_category metadata during transformation
transformer_func=lambda: filter_and_transform(
table="centralized_audit_logs.prod",
metadata_filter="cluster_type = 'CONTROL_PLANE'",
service_category="control_plane"
)This pattern enables:
Centralized logging without losing service-specific context
Per-service transformations from shared tables
Independent schema evolution for each service category
Cost optimization through table consolidation
The alternative - separate tables per service - creates exponential maintenance burden as you add services and clouds.
Core Design Principles:
Hierarchical Structure Over Flat Fields: Invest significant time in data modeling upfront. A well-designed nested schema prevents cascading failures when fields change. Avoid flat structures where changing one element breaks everything downstream.
Stable Top-Level Parents: Design parent fields that rarely change: user, resource, network, action. These become your API contract with downstream consumers. Nested children can evolve freely without breaking detection rules or dashboards.
The Universal Security Event Schema:
A well-designed normalized schema for cloud security events contains these core top-level fields:
normalized_security_event:
cloud_api_action: "string" # Raw cloud provider API call
principal:
type: "User|ServiceAccount" # Enum - constrained values
identity: "string" # Principal identifier
ip:
address: "string" # Source IP address
metadata: {} # Geo, ASN, threat intel (nested)
resource:
type: "string" # Resource being acted upon
identifier: "string" # Resource ID/ARN/URI
metadata: {} # Classification, tags (nested)
action:
type: "CreateInstance|DeleteInstance|CreateToken|UpdateBucketPolicy|..." # Enum
verb: "create|delete|modify|access" # Semantic action classificationThis structure provides stability (top-level fields never change) while allowing extensibility (metadata objects can evolve). The use of enums for principal.type and action.type ensures type safety and prevents drift.
Schema Serialization: The Production-Grade Approach
Here’s a critical insight that separates mature security data platforms from fragile ones: use serialized configuration that enforces schema compliance through code, not hope.
The anti-pattern teams fall into: spend months carefully data modeling a unified schema, then normalize logs with ad-hoc functions, hoping the output matches the schema. Someone adds new fields to the normalization logic six months later without updating the schema definition. Suddenly, downstream detection rules break because they’re receiving unexpected columns, or worse, pipelines silently drop data because fields don’t match the expected structure.
The production-grade approach: use Protocol Buffers, Avro, or similar serialization frameworks that enforce schema contracts. When you deserialize (unmarshal) raw logs into your normalized schema, the serialization library validates every field. Extra columns? Compilation error. Missing required fields? Runtime exception before the data reaches production. Schema version mismatch? Caught immediately, not three days later when analysts notice detection gaps.
This approach provides schema evolution safety. Before any normalization code change reaches production, serialization tests validate that outputs conform to the unified schema. This catches discrepancies at development time, not when you’re explaining to leadership why 20% of security alerts went missing for a week. The upfront investment in schema serialization infrastructure pays exponential dividends by eliminating an entire class of production failures.
YAML-Based Normalization Configuration
Replace hardcoded mapping logic with configuration-driven adapters. This transforms schema updates from engineering projects into configuration changes.
# aws_normalization.yaml
provider: "aws"
log_type: "cloudtrail"
# Field mappings - declarative, not programmatic
field_mappings:
# User identity mapping
user.identity:
source: "userIdentity.principalId"
fallback: "userIdentity.userName"
user.type:
source: "userIdentity.type"
transform:
"IAMUser": "human"
"AssumedRole": "service_account"
"Root": "system"
# Resource mapping
resource.type:
source: "eventName"
transform:
"RunInstances": "compute"
"CreateBucket": "storage"
"CreateDBInstance": "database"
resource.tags:
source: "requestParameters.tagSpecificationSet.items"
# Network mapping
network.source_ip: "sourceIPAddress"
# Action mapping
action.type:
source: "eventName"
transform:
"RunInstances": "create"
"TerminateInstances": "delete"
"ModifyInstanceAttribute": "modify"
# Timestamp mapping
event.timestamp:
source: "eventTime"
# Enrichment rules (basic metadata only in Silver layer)
enrichment_rules:
- condition: "action.type == 'create' AND resource.type == 'compute'"
enrich:
resource.metadata.instance_type:
source: "requestParameters.instanceType"The Type Safety Progression:
Production teams should follow this maturity path:
Simple YAML (shown above) - Start here for rapid prototyping and immediate accessibility
Validated YAML - Add Pydantic, JSON Schema, or Cerberus for runtime type checking and required field validation
Protocol Buffers - Graduate to compile-time type safety for large-scale production environments
This progression balances accessibility with rigor. Start simple, add validation as you scale, migrate to Protocol Buffers when type safety becomes critical.
Adding Oracle Cloud becomes a new configuration file, not a code rewrite. Implementation time: 2-3 days instead of 2-3 months.
Production Note: YAML vs. Protocol Buffers
While YAML provides excellent readability and immediate accessibility, production-grade implementations should enforce schema validation. Two approaches:
YAML + Validation Library: Combine YAML with Pydantic (Python), JSON Schema, or Cerberus to validate structure at runtime
Protocol Buffers: Get compile-time type safety and schema enforcement through code generation
YAML is ideal for teams starting their normalization journey - lower barrier to entry, familiar tooling. Protocol Buffers excel in large-scale production environments requiring strict type safety and cross-language compatibility. The configuration patterns remain identical; only the enforcement mechanism differs.
Alternative: Protocol Buffer Implementation
For teams requiring compile-time schema validation and type safety, Protocol Buffers provide a robust alternative to YAML.
Define the Protocol Buffer schema (normalization_config.proto):
syntax = "proto3";
package normalization;
message TransformMap {
map<string, string> mappings = 1;
}
message FieldMapping {
string source = 1;
string fallback = 2;
TransformMap transform = 3;
}
message EnrichmentRule {
string condition = 1;
map<string, FieldMapping> enrich = 2;
}
message NormalizationConfig {
string provider = 1;
string log_type = 2;
map<string, FieldMapping> field_mappings = 3;
repeated EnrichmentRule enrichment_rules = 4;
}Resulting text proto (aws_normalization.textproto):
provider: "aws"
log_type: "cloudtrail"
field_mappings {
key: "user.identity"
value {
source: "userIdentity.principalId"
fallback: "userIdentity.userName"
}
}
field_mappings {
key: "user.type"
value {
source: "userIdentity.type"
transform {
mappings {
key: "IAMUser"
value: "human"
}
mappings {
key: "AssumedRole"
value: "service_account"
}
}
}
}Benefits of Protocol Buffers:
Compile-time validation: Schema violations caught during code generation
Type safety: Field types enforced by the compiler
Cross-language: Generate parsers for Python, Go, Java, C++ from same .proto
Version control: Schema evolution tracked through proto versioning
Performance: Binary serialization faster than YAML parsing
When to use Protocol Buffers:
Large-scale production environments (>1TB/day log volume)
Multi-language normalization pipelines (Python ingestion, Go processing, Java analytics)
Teams with strong software engineering practices (CI/CD, code review, testing)
Requirements for strict schema governance and audit trails
Production-Grade Implementation Patterns
Moving from normalization theory to production reality requires architectural patterns that handle scale, change, and organizational complexity. Here are three critical patterns that separate teams who successfully operationalize normalization from those who struggle.
Pattern 1: Declarative Service Registry
The extensibility problem isn’t just schema design - it’s operational: how do you add new cloud providers without modifying core logic everywhere?
The Anti-Pattern: Hard-coded transformation logic scattered across the codebase. Adding Oracle requires changing 15 different files, updating documentation separately, and hoping you found all the dependencies.
The Pattern: Build a self-documenting service registry where each data source is a declarative configuration entry.
@dataclass
class ServiceConfig:
service_name: str # "compute_oracle"
cloud_provider: str # "oracle"
service_category: str # "compute" | "storage" | "control_plane"
input_tables: List[str] # ["oracle.cloud_audit_logs"]
date_column: str # "date"
transformer_func: Callable # transform_oracle_logs
description: str
# Global registry
SERVICE_REGISTRY: Dict[str, ServiceConfig] = {}
def register_service(config: ServiceConfig):
"""Single source of truth for all normalization sources"""
SERVICE_REGISTRY[config.service_name] = configAdding Oracle becomes:
register_service(ServiceConfig(
service_name="compute_oracle",
cloud_provider="oracle",
service_category="compute",
input_tables=["oracle.cloud_audit_logs"],
date_column="timestamp",
transformer_func=transform_oracle_logs,
description="Oracle Cloud compute audit logs"
))Benefits:
Self-documenting: Registry is living documentation of all sources
Single point of change: Adding a provider touches one location
Discoverable:
list(SERVICE_REGISTRY.keys())shows all available sourcesTestable: Registry can be mocked for unit tests
Real Impact: Organizations with mature normalization infrastructure report significant time reduction when adding new cloud providers:
Without registry: Weeks to months (rewrite transformation logic, update detections, test comprehensively)
With registry: Days to weeks (add ServiceConfig entry, validate schema compliance)
The exact timeline depends on organizational maturity. Initial normalization infrastructure requires upfront investment. Once established, adding subsequent providers becomes a configuration change rather than a development project.
Pattern 2: Transformation-Detection Separation
This pattern operationalizes the “schema-first detection engineering” principle through clear architectural boundaries.
The Architecture
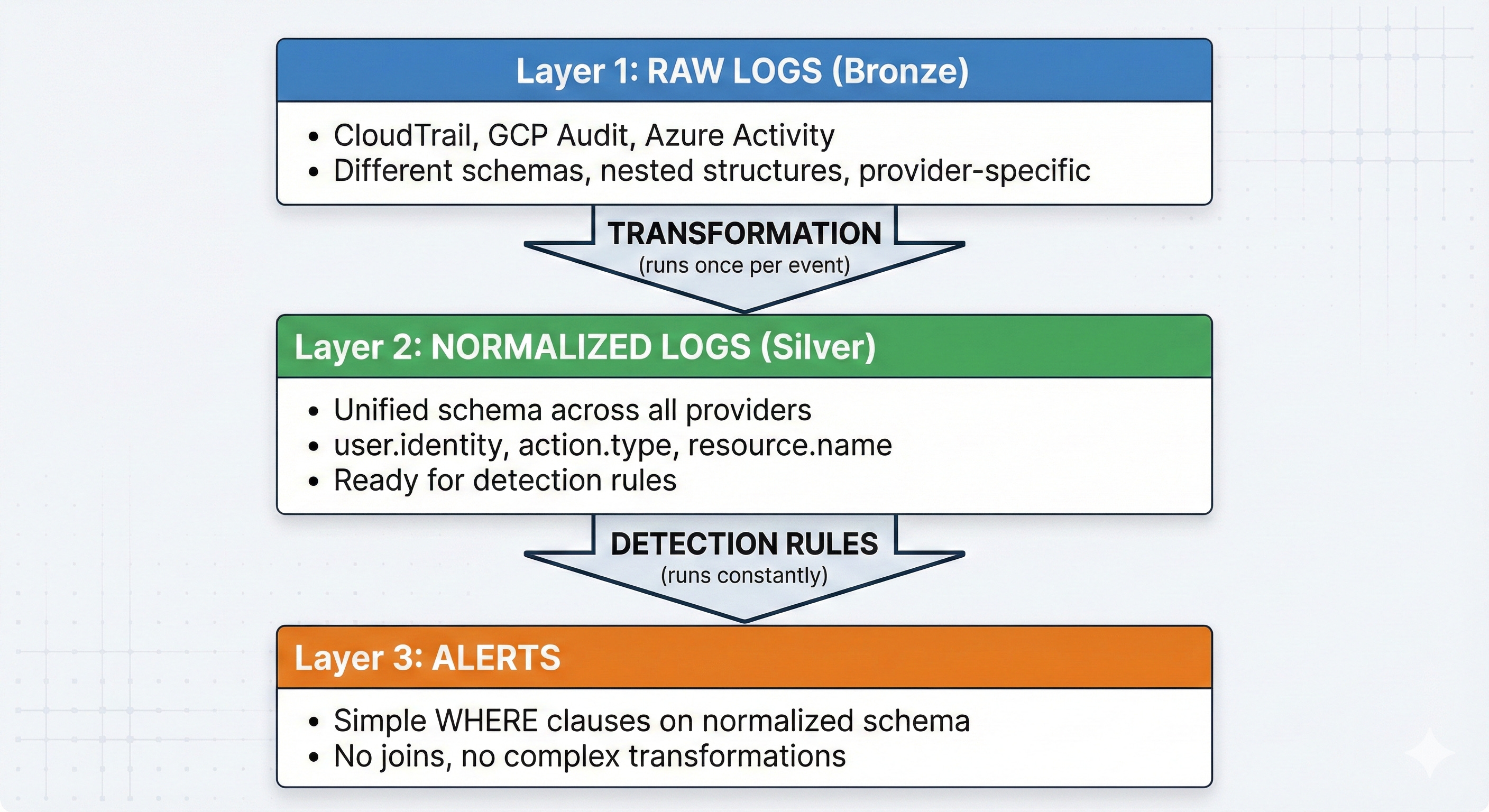
The Key Insight: Complexity should live in the transformation layer (which runs once during normalization) not in the detection layer (which runs constantly on every query).
Benefits:
Separation of concerns: Data engineers own transformation, detection engineers own rules
Performance: Transformations cached in Silver layer, not recomputed per query
Testability: Can test transformations independently from detections
Maintainability: Schema changes impact transformation layer only
What This Enables: Junior analysts can write detections confidently because the schema is stable and well-documented. Senior engineers can optimize transformations without touching detection logic.
Pattern 3: Wrapper Pattern for Dependency Injection
This pattern makes transformation functions testable, reusable, and environment-agnostic.
The Problem: Transformation functions hard-coded to specific execution contexts (database connections, compute engines, configuration objects). Testing requires spinning up entire infrastructure.
The Pattern:
# Bad: Hard-coded dependencies
def transform_aws_logs(lookback_days: int):
# Implicitly depends on global database connection
df = db_connection.read_table("cloudtrail_logs")
# Implicitly depends on global config
region_mapping = GLOBAL_CONFIG['regions']
return df.transform(...)
# Good: Dependency injection via wrapper
def transform_aws_logs(
lookback_days: int,
data_engine,
config: dict
):
"""Pure function - all dependencies explicit"""
df = data_engine.read_table("cloudtrail_logs")
region_mapping = config['regions']
return df.transform(...)
# Wrapper injects dependencies
def create_transformer_wrapper(transform_func, config):
"""Factory pattern for production context"""
def wrapper(lookback_days: int):
return transform_func(
lookback_days=lookback_days,
data_engine=engine, # Injected (Spark/Pandas/DuckDB/etc)
config=config # Injected
)
return wrapper
# Register with injected dependencies
register_service(ServiceConfig(
service_name="aws_cloudtrail",
transformer_func=create_transformer_wrapper(
transform_aws_logs,
production_config
),
...
))Testing Becomes Trivial:
# Unit test with mock dependencies
def test_transform_aws_logs():
mock_engine = create_mock_data_engine()
test_config = {'regions': TEST_REGION_MAP}
result = transform_aws_logs(
lookback_days=1,
data_engine=mock_engine,
config=test_config
)
assert result.schema == EXPECTED_SCHEMABenefits:
Testability: Can test with mocks, no infrastructure required
Reusability: Same transformation function works in dev/staging/prod
Clarity: All dependencies explicit in function signature
Flexibility: Easy to swap implementations (Spark vs. Pandas vs. DuckDB vs. Polars)
Production Impact: Teams can run comprehensive transformation tests in CI/CD without spinning up clusters. Test execution time drops from 30 minutes to 30 seconds.
Bringing It Together
These three patterns create a production normalization system that:
Service Registry - Makes adding new sources a configuration change, not a development project
Transformation-Detection Separation - Keeps complexity in the right layer, makes detections simple
Dependency Injection - Makes everything testable, flexible, and maintainable
The Compound Effect:
Without these patterns:
Adding Oracle: 2-3 months of development
Writing new detection: 2-3 hours (complex joins and transformations)
Running tests: 30 minutes (requires full infrastructure)
With these patterns:
Adding Oracle: 2-3 days of configuration
Writing new detection: 5-10 minutes (simple WHERE clauses)
Running tests: 30 seconds (mocked dependencies)
This is the difference between normalization as a theoretical benefit and normalization as an operational multiplier.
Schema Evolution Without Breaking Dependencies
Schema changes must consider downstream impact across detection rules, dashboards, and analytics pipelines. The solution is additive evolution with stable contracts.
Never modify existing field paths. Instead of changing user.identity to user.principal, add user.principal and deprecate user.identity over time. Use semantic versioning for schemas. Version 2.1 can add fields. Version 3.0 can remove deprecated fields. Detection rules specify compatible schema versions. Implement schema compatibility testing. Before deploying schema changes, validate that existing detection rules still parse correctly.
# Schema compatibility validation
compatibility_tests:
- name: "public_bucket_detection_v1.0"
query: |
SELECT * FROM events
WHERE event.action = 'storage.bucket.permission.update'
AND storage.permission.public_access = true
expected_fields: ["user.identity", "event.action", "storage.permission.public_access"]
schema_versions: ["2.0", "2.1", "2.2"]Detection Rules Must Mirror Normalized Schema
This is where most normalization efforts fail. Teams invest months building normalized schemas, then write detection rules against raw log formats, negating all benefits.
Rule: If you normalize to schema X, detection rules must query schema X.
-- WRONG: Mixing normalized and raw formats
SELECT user.identity, sourceIPAddress, eventName
FROM security_events
WHERE user.type = 'service_account'
AND sourceIPAddress LIKE '10.%' -- Raw CloudTrail field
-- RIGHT: Pure normalized schema
SELECT user.identity, network.source_ip, action.type
FROM security_events
WHERE user.type = 'service_account'
AND network.source_ip LIKE '10.%' -- Normalized field
AND action.type = 'create' -- Normalized fieldSchema-Detection Parity Principle: When upstream schemas change, both normalized logs and detection rules automatically stay synchronized. Spend time data modeling once, benefit everywhere.
Practical Detection: Write Once, Deploy Everywhere
Let’s see this in action with a critical security event: detecting when admin/owner privileges are granted to user accounts - a common indicator of privilege escalation attacks.
Without Normalization (The Old Way)
AWS Detection:
SELECT * FROM cloudtrail_logs
WHERE eventName IN ('AttachUserPolicy', 'PutUserPolicy')
AND requestParameters.policyArn LIKE '%AdministratorAccess%'
OR requestParameters.policyDocument LIKE '%"Effect":"Allow"%"Action":"*"%'GCP Detection:
SELECT * FROM gcp_audit_logs
WHERE methodName = 'google.iam.admin.v1.SetIamPolicy'
AND protoPayload.request.policy.bindings.role IN ('roles/owner', 'roles/editor')
AND protoPayload.request.policy.bindings.members LIKE 'user:%'Azure Detection:
SELECT * FROM azure_activity_logs
WHERE operationName = 'Microsoft.Authorization/roleAssignments/write'
AND properties.requestBody LIKE '%/providers/Microsoft.Authorization/roleDefinitions/%Owner%'
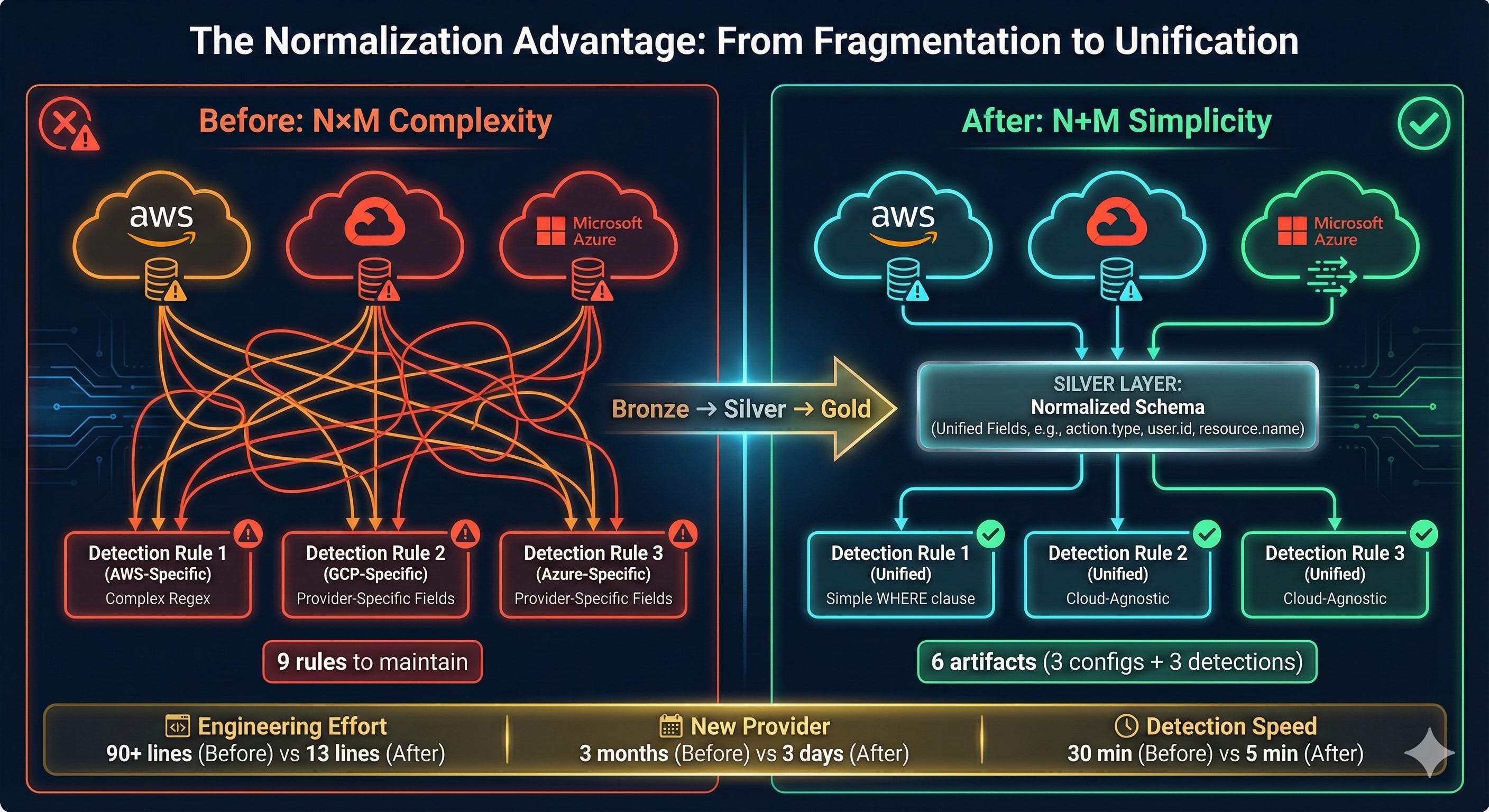
OR properties.requestBody LIKE '%Contributor%'Total engineering effort: 3 rules to write, 3 rules to test, 3 rules to maintain. Each cloud provider addition triples your workload. Each rule requires deep knowledge of provider-specific API structures.
With Normalization (The New Way)
Universal Detection:
SELECT
user.identity,
action.type,
resource.role_name,
cloud.provider,
cloud.account_id
FROM cloud_audit_logs_silver
WHERE action.type = 'role-assign'
AND resource.role_name RLIKE '(Admin|Owner|root|FullAccess|Editor)'
AND user.type = 'human'
AND cloud.provider IN ('aws', 'gcp', 'azure')Total engineering effort: 1 rule. Works everywhere. Forever.
Key indicators normalized:
Role assignment actions across all clouds →
action.type = 'role-assign'High-privilege role names standardized →
resource.role_name RLIKE '(Admin|Owner|root)'Human vs service account distinction →
user.type = 'human'
The normalized schema abstracts away the complexity:
AWS:
AttachUserPolicy+ policy ARN parsing →action.type = 'role-assign'GCP:
SetIamPolicy+ bindings extraction →action.type = 'role-assign'Azure:
roleAssignments/write+ role definition parsing →action.type = 'role-assign'
Engineering effort: 3x reduced to 1x.
High quality detections require high quality data.
Security engineers need to think like data engineers.
The Economics: Why Normalization Wins
The traditional approach to multi-cloud detection creates exponential complexity. With 3 cloud providers and 10 detection use cases, you maintain 30 separate rules. Add Oracle and Alibaba, and you’re at 50 rules. The maintenance burden grows as N×M (providers × detections).
With normalization, maintenance complexity becomes N+M. You maintain one normalization config per provider (5 configs) and one detection rule per use case (10 rules). Total: 15 artifacts instead of 50. As you add providers or detections, the gap widens exponentially.
Note: While maintenance is linear, comprehensive validation requires testing each detection against each provider’s normalized output to ensure transformation accuracy. This testing effort is significantly reduced compared to maintaining separate detection logic, but remains an important quality assurance step.
Engineering Productivity:
Detection development: 30 minutes → 5 minutes (6x faster)
Multi-cloud coverage: 3 rules → 1 rule (3x reduction)
New provider onboarding: 2-3 months → 2-3 days (30x faster)
Operational Benefits:
Schema compatibility testing catches breaking changes before production
Detection portability enables instant multi-cloud coverage
Configuration-driven adapters eliminate hardcoded logic debt
A Call to Action: Invest Upstream
If you’re spending more time writing provider-specific detection rules than designing robust schemas, you’re doing it backwards.
The solution isn’t more SIEM connectors. It’s not better threat intelligence feeds. It’s not hiring more detection engineers. The solution is investing upstream in normalization architecture.
Organizations that build Bronze-Silver foundations will write detections once and deploy everywhere, onboard new cloud providers in days not months, maintain schema compatibility across the entire detection stack, and scale detection engineering without linear headcount growth.
Organizations that skip normalization will continue writing N×M detection rules, spending months onboarding each new cloud provider, breaking detections with every schema change, and wondering why their detection coverage has so many gaps.
The Bottom Line
Stop treating schema normalization as an afterthought.
The Bronze-Silver architecture isn’t just about data engineering - it’s about building detection infrastructure that scales. When you normalize once and detect everywhere, you transform security operations from a maintenance burden into a strategic capability.
The industry’s fragmented approach to multi-cloud detection has created technical debt that compounds daily. The paradigm shift to normalization-first architecture isn’t just best practice - it’s survival.
The question isn’t whether to normalize. It’s whether you’ll lead this shift or be left maintaining 50+ provider-specific detection rules while your competitors deploy universal detections in minutes.
In the next article, we’ll explore how the Gold layer enrichment transforms these normalized detections from alerts into actionable intelligence, and how AI-powered agents leverage that context for autonomous security operations.